Python SDK 使用说明
最后更新于:2018-10-26 10:26:00
在使用前,请先阅读数据模型的介绍。
1. 集成神策分析 SDK
在 Python 脚本中集成神策分析 SDK,使用神策分析采集并分析用户数据。
我们推荐使用 pip 管理 Python 项目并获取神策分析 SDK:
pip install SensorsAnalyticsSDK
如果不使用 pip,也可以从 Github 下载神策分析 SDK 的源代码。
SDK 兼容 Python 2.6+ 和 Python3 3.X,不依赖第三方库。
2. 初始化神策分析 SDK
2.1 获取配置信息
首先从神策分析的主页中,获取数据接收的 URL 和 Token(Cloud 版)。
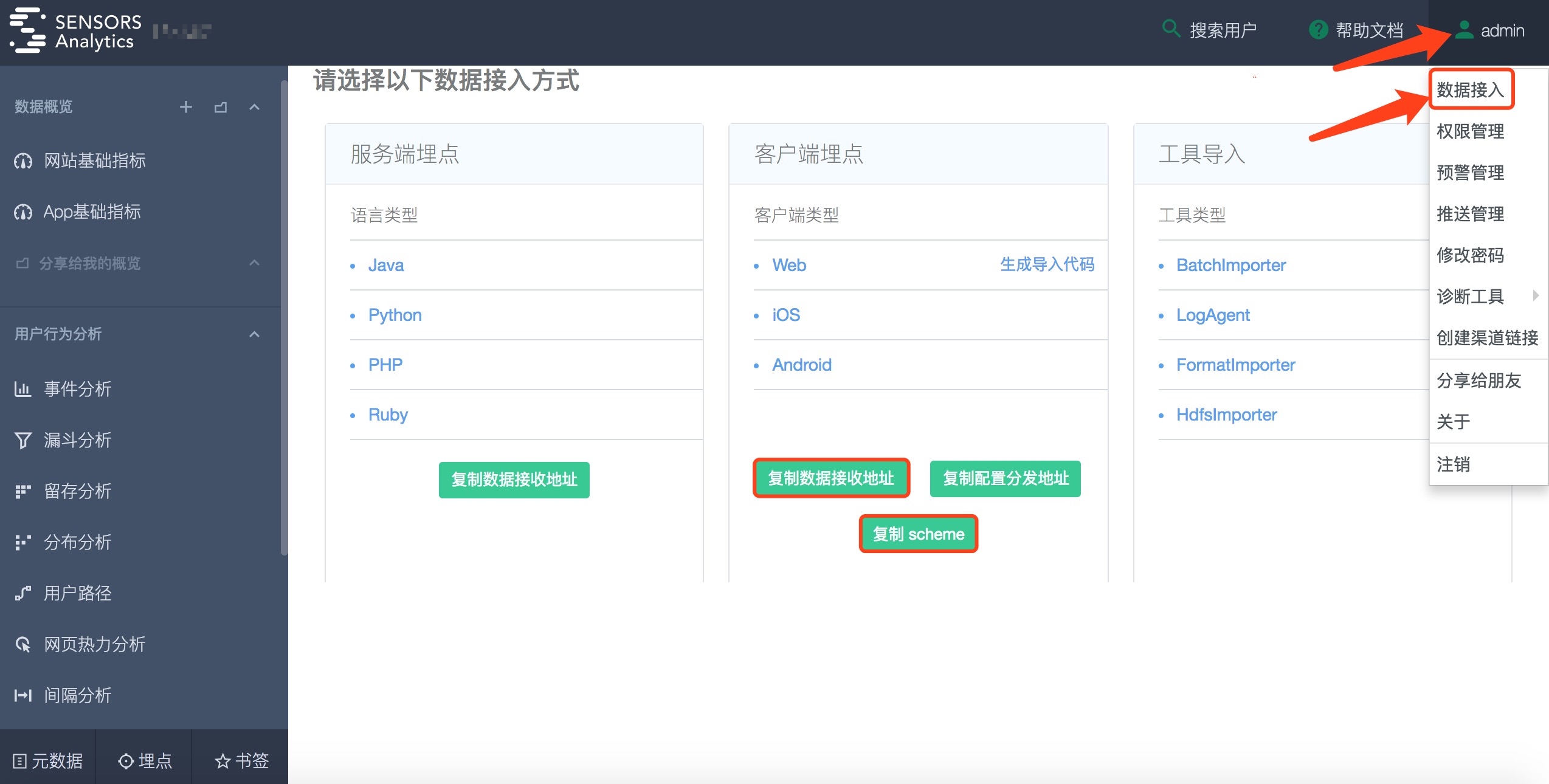
如果使用神策分析 Cloud 服务,需获取的配置信息为:
- 数据接收地址,建议使用不带端口号的: http://{$service_name}.datasink.sensorsdata.cn/sa?project={$project_name}&token={$project_token}
- 数据接收地址,带端口号的: http://{$service_name}.cloud.sensorsdata.cn:8106/sa?project={$project_name}&token={$project_token}
如果用户使用单机版私有部署的神策分析,默认的配置信息为:
- 数据接收地址: http://{$host_name}:8106/sa?project={$project_name} (注:神策分析 1.7 及之前的版本,单机版私有部署默认端口号为 8006)
如果用户使用集群版私有部署的神策分析,默认的配置信息为:
其中 {$host_name} 可以是集群中任意一台机器。
如果私有部署的过程中修改了 Nginx 的默认配置,或通过 CDN 等访问神策分析,则请咨询相关人员获得配置信息。
2.2 在程序中初始化 SDK
在程序中初始化的代码段中构造神策分析 SDK 的实例:
import sensorsanalytics
# 从神策分析配置页面中获取数据接收的 URL
SA_SERVER_URL = 'YOUR_SERVER_URL'
# 初始化一个 Consumer,用于数据发送
# DefaultConsumer 是同步发送数据,因此不要在任何线上的服务中使用此 Consumer
consumer = sensorsanalytics.DefaultConsumer(SA_SERVER_URL)
# 使用 Consumer 来构造 SensorsAnalytics 对象
sa = sensorsanalytics.SensorsAnalytics(consumer)
# 记录用户登录事件
distinct_id = 'ABCDEF123456789'
sa.track(distinct_id, 'UserLogin', is_login_id=True)
sa.close()
其中 YOUR_SERVER_URL 是前文中从神策分析获取的数据接收的 URL。用户程序应该一直持有该实例,直到程序结束。程序退出前,需要使用 close() 方法显式关闭,否则可能丢失部分缓存的数据。
至此,我们已经可以正常使用神策分析 SDK 了。需了解更多关于 SDK 的使用方法,可以跳到本文末尾的 控制神策分析 SDK 一节。
3. 追踪事件
第一次接入神策分析时,建议先追踪 3~5 个关键的事件,只需要几行代码,便能体验神策分析的分析功能。例如:
- 图片社交产品,可以追踪用户浏览图片和评论事件
- 电商产品,可以追踪用户注册、浏览商品和下订单等事件
用户通过 track() 接口记录事件,对于任何事件,必须包含用户标志符(distinct_id)和事件名(event_name)两个参数。同时,用户可以在 track() 的第三个参数传入一个 dict 对象,为事件添加自定义事件属性。以电商产品为例,可以这样追踪一次购物行为:
distinct_id = 'ABCDEF123456'
properties = {
# '$time' 属性是系统预置属性,传入 datetime 对象,表示事件发生的时间,如果不填入该属性,则默认使用系统当前时间
'$time' : datetime.datetime.now(),
# '$ip' 属性是系统预置属性,如果服务端中能获取用户 IP 地址,并填入该属性,神策分析会自动根据 IP 地址解析用户的省份、城市信息
'$ip' : '123.123.123.123',
# 商品 ID
'ProductId' : '123456',
# 商品类别
'ProductCatalog' : 'Laptop Computer',
# 是否加入收藏夹,Boolean 类型的属性
'IsAddedToFav' : True,
}
# 记录用户浏览商品事件
sa.track(distinct_id, 'ViewProduct', properties, is_login_id=True)
properties = {
# 用户 IP 地址
'$ip' : '123.123.123.123',
# 商品 ID 列表,list<str> 类型的属性
'ProductIdList' : ['123456', '234567', '345678'],
# 订单价格
'OrderPaid' : 12.10,
}
# 记录用户订单付款事件
sa.track(distinct_id, 'PaidOrder', properties, is_login_id=True)
3.1 事件属性
如前文中的样例,追踪的事件可以设置自定义的事件属性,例如浏览商品事件中,将商品 ID、商品分类等信息作为事件属性。在后续的分析工作中,事件属性可以作为统计过滤条件使用,也可以作为维度进行多维分析。对于事件属性,神策分析有一些约束:
- 事件属性是一个
dict对象 dict中每个元素描述一个属性,Key 为属性名称,必需是str类型dict中,每个元素的 Value 是属性的值,支持str、int、float、list、datetime.datetime和datetime.date
对于神策分析中事件属性的更多约束,请参考 数据格式
3.1.1 系统预置属性
如前文中样例,事件属性中以 '$' 开头的属性为系统预置属性,在自定义事件属性中填入对应 '$' 开头的属性值可以覆盖这些预置属性:
$ip- 填入该属性,神策分析会自动根据 IP 地址解析用户的省份、城市信息,该属性值为str类型;$time- 填入该属性,神策分析将事件时间设置为属性值的时间,该属性值必须为datetime.datetime或datetime.date类型。请注意,神策分析默认会过滤忽略 365 天前或 3 天后的数据,如需修改请联系我们。
关于其他更多预置属性,请参考 数据格式 中 '预置属性' 一节。
4. 用户识别
在服务端应用中,神策分析也要求为每个事件设置用户的 Distinct Id,这有助于神策分析提供更准确的留存率等数据。
对于注册用户,推荐使用系统中的用户 ID 作为 Distinct Id,不建议使用用户名、Email、手机号码等可以被修改的信息。对于未注册的匿名用户,服务端也需要生成一个随机 ID 以标记用户。
所有的 track 和 profile 系列方法建议明确指定 is_login_id 参数,以便明确告知神策分析用户 ID 的类型。
4.1 用户注册/登录
当同一个用户的 Distinct Id 发生变化时(一般情况为匿名用户注册行为),可以通过 track_signup() 将旧的 Distinct Id 和新的 Distinct Id 关联,以保证用户分析的准确性。例如:
# 匿名ID 由前端传过来
anonymous_id = '9771C579-71F0-4650-8EE8-8999FA717761'
register_id = '0012345678'
# 用户注册/登录时,将用户注册 ID 与 匿名 ID 关联
sa.track_signup(register_id, anonymous_id)
注意,对同一个用户,track_signup() 只可调用一次(通常在用户 注册 时调用),多次调用 track_signup() 时,只有第一次关联行为是有效的。用户 登录 前后的行为的关联建议在业务端实现。更详细的说明请参考 如何准确的标识用户,并在必要时联系我们的技术支持人员。
5. 设置用户属性
为了更准确地提供针对人群的分析服务,神策分析 SDK 可以设置用户属性,如年龄、性别等。用户可以在留存分析、分布分析等功能中,使用用户属性作为过滤条件或以用户属性作为维度进行多维分析。
使用 profile_set() 设置用户属性:
distinct_id = 'ABCDEF123456789'
properties = {
# 用户性别属性(Sex)为男性
'Sex' : 'Male',
# 用户等级属性(Level)为 VIP
'UserLevel' : 'Elite VIP',
}
# 设置用户属性
sa.profile_set(distinct_id, properties, is_login_id=True)
对于不再需要的用户属性,可以通过 profile_unset() 接口将属性删除。
用户属性中,属性名称与属性值的约束条件与事件属性相同,详细说明请参考 数据格式。
5.1 记录初次设定的属性
对于只在首次设置时有效的属性,我们可以使用 profile_set_once() 记录这些属性。与 profile_set() 接口不同的是,如果被设置的用户属性已存在,则这条记录会被忽略而不会覆盖已有数据>,如果属性不存在则会自动创建。因此,profile_set_once() 比较适用于为用户设置首次激活时间、首次注册时间等属性。例如:
distinct_id = 'ABCDEF123456789'
# 设置用户渠道属性(AdSource)为 "App Store"
sa.profile_set_once(distinct_id, {'AdSource' : 'App Store'})
# 再次设置用户渠道属性(AdSource),设定无效,属性 "AdSource" 的值仍为 "App Store"
sa.profile_set_once(distinct_id, {'AdSource' : 'Search Engine'})
5.2 数值类型的属性
对于数值型的用户属性,可以使用 profile_increment() 对属性值进行累加。常用于记录用户付费次数、付费额度、积分等属性。例如:
distinct_id = 'ABCDEF123456789'
# 设置用户游戏次数属性(GamePlayed),将次数累加1次
sa.profile_increment(distinct_id, {'GamePlayed' : 1}, is_login_id=True)
5.3 列表类型的属性
对于用户喜爱的电影、用户点评过的餐厅等属性,可以记录列表型属性。需要注意的是,列表型属性中的元素必须为 str 类型,且元素的值会自动去重。关于列表类型限制请见 数据格式 7.3 属性长度限制。
distinct_id = 'ABCDEF123456789'
properties = {
# 电影列表
'Movies' : ['Sicario', 'Love Letter'],
# 游戏列表
'Games' : ['Call of Duty', 'Halo'],
}
# 传入properties,设置用户喜欢的电影属性(movies)和喜欢的游戏属性(games)
# 设置成功后,"Movies" 属性值为 ["Sicario", "Love Letter"];"Games" 属性值为 ["Call of Duty", "Halo"]
sa.profile_append(distinct_id, properties, is_login_id=True)
# 传入属性名称和需要插入属性的值,设置用户喜欢的电影属性(Movies)
# 设置成功后 "Movies" 属性值为 ["Sicario", "Love Letter", "Dead Poets Society"]
sa.profile_append(distinct_id, {'Movies' : ['Dead Poets Society']}, is_login_id=True)
# 传入属性名称和需要插入属性的值,设置用户喜欢的电影属性(Movies),
# 但属性值 "Love Letter" 与已列表中已有元素重复,操作无效,
# "Movies" 属性值仍然为 ["Sicario", "Love Letter", "Dead Poets Society"]
sa.profile_append(distinct_id, {'Movies' : ['Love Letter']}, is_login_id=True)
6. 物品元数据上报
在神策推荐项目中,客户需要将物品元数据上报,以开展后续推荐业务的开发与维护。神策分析SDK提供了设置与删除物品元数据的方法。
item_id(物品 ID )与 item_type (物品所属类型)共同组成了一个物品的唯一标识。所有的 item 系列方法都必须同时指定物品 ID 及物品所属类型这两个参数,来完成对物品的操作。
6.1 设置物品
直接设置一个物品,如果已存在则覆盖。除物品 ID 与 物品所属类型外,其他物品属性需在 $properties 中定义。
物品属性中,属性名称与属性值的约束条件与事件属性相同,详细说明请参考 数据格式。
# 例如
item_type = 'apple'
item_id = '12345'
sa.item_set(item_type, item_id, {"price": "3"})
6.2 删除一个物品
如果物品不可被推荐需要下线,删除该物品即可,如不存在则忽略。
除物品 ID 与 物品所属类型外,不解析其他物品属性。
# 例如
item_type = 'apple'
item_id = '12345'
sa.item_delete(item_type, item_id)
7. 设置神策分析 SDK
Python SDK 主要由以下两个组件构成:
- SensorsAnalytics: 用于发送数据的接口对象,构造函数需要传入一个 Consumer 实例。
- Consumer: Consumer 会进行实际的数据发送
为了让开发者更灵活的接入数据,神策分析 SDK 实现了以下 Consumer:
7.1 LoggingConsumer(推荐)
用于将数据输出到指定目录并按天切割文件,一般用于在 Python 脚本中处理实时数据,生成日志文件并使用 LogAgent 等工具导入。
import sensorsanalytics
# 初始化 Logging Consumer
consumer = sensorsanalytics.LoggingConsumer('/data/sa/access.log')
# 使用 Consumer 来构造 SensorsAnalytics 对象
sa = sensorsanalytics.SensorsAnalytics(consumer)
可以通过参数配置切分间隔和保留的文件数,默认是每天0点切割,保留所有文件。具体参数含义参考Python 标准库 logging.handlers.TimedRotatingFileHandler 文档。
# 按小时切分,保留最近10个文件
consumer = sensorsanalytics.LoggingConsumer('/data/sa/access.log', backupCount=10, when='H')
注意,请不要使用多进程写入同一个日志文件,可能会造成数据丢失或者错乱。如果需要多进程写入,请使用 ConcurrentLoggingConsumer。
7.2 ConcurrentLoggingConsumer(推荐)
用于将数据输出到指定目录,并自动按 天 切割文件,与 LoggingConsumer 不同的是,它支持多进程写入同一个文件。一般用于 Django、uWSGI 等特殊的多进程场景。
import sensorsanalytics
# 当缓存的数据量达到参数值时,批量向文件中写入数据
SA_BULK_SIZE = 1024
# 初始化 Concurrent Logging Consumer,写入文件 '/data/sa/access.log.YYYY-MM-DD' 中,日志缓冲区长度为 1024 条
consumer = sensorsanalytics.ConcurrentLoggingConsumer('/data/sa/access.log', SA_BULK_SIZE)
# 使用 Consumer 来构造 SensorsAnalytics 对象
sa = sensorsanalytics.SensorsAnalytics(consumer)
# ...
# 程序结束前调用 flush() ,通知 Consumer 发送所有缓存数据
sa.flush()
注意: LogAgent 配置文件中一定要注释掉 real_time_file_name 参数,否则无法正常导入数据。已使用 LoggingConsumer 的客户建议按照如下步骤切换到 ConcurrentLoggingConsumer:
第 1 步 停掉 LogAgent,并注释掉 LogAgent 配置中的 real_time_file_name 参数。 第 2 步 将日志目录下的 real_time_file_name 的文件加上当前时间的后缀 ".YYYY-MM-DD"。 第 3 步 后端程序升级切换到 ConcurrentLoggingConsumer。 第 4 步 重新启动 LogAgent。
7.3 DebugConsumer(测试使用)
用于校验数据导入是否正确,关于 Debug 模式 的详细信息,请进入相关页面查看。请注意,不要在生产环境中使用 Debug 模式。
import sensorsanalytics
# 神策分析数据接收的 URL
SA_SERVER_URL = 'YOUR_SERVER_URL'
# 发送数据的超时时间,单位毫秒
SA_REQUEST_TIMEOUT = 100000
# Debug 模式下,是否将数据导入神策分析
# True - 校验数据,并将数据导入到神策分析中
# False - 校验数据,但不进行数据导入
SA_DEBUG_WRITE_DATA = True
# 初始化 Debug Consumer
consumer = sensorsanalytics.DebugConsumer(SA_SERVER_URL, SA_DEBUG_WRITE_DATA, SA_REQUEST_TIMEOUT)
# 使用 Consumer 来构造 SensorsAnalytics 对象
sa = sensorsanalytics.SensorsAnalytics(consumer)
7.4 ConsoleConsumer
用于将数据输出到标准输出,一般用于在 Python 脚本中处理历史数据,生成日志文件并使用 BatchImporter 等工具导入。
import sensorsanalytics
# 初始化 Console Consumer
consumer = sensorsanalytics.ConsoleConsumer()
# 使用 Consumer 来构造 SensorsAnalytics 对象
sa = sensorsanalytics.SensorsAnalytics(consumer)
7.5 DefaultConsumer
通常用于导入小规模历史数据。由于是同步发送数据,因此不要用在任何线上的服务中。 普通 Consumer,实现,逐条、同步的发送数据给接收服务器。
import sensorsanalytics
# 神策分析数据接收的 URL
SA_SERVER_URL = 'YOUR_SERVER_URL'
# 发送数据的超时时间,单位毫秒
SA_REQUEST_TIMEOUT = 100000
# 初始化 Default Consumer
consumer = sensorsanalytics.DefaultConsumer(SA_SERVER_URL, SA_REQUEST_TIMEOUT)
# 使用 Consumer 来构造 SensorsAnalytics 对象
sa = sensorsanalytics.SensorsAnalytics(consumer)
7.6 BatchConsumer
通常用于导入小规模历史数据,或者离线 / 旁路导入数据的场景。由于是同步发送数据,因此不要用在任何线上的服务中。 批量发送数据的 Consumer,当且仅当数据达到指定的量时,才将数据进行发送。
import sensorsanalytics
# 神策分析数据接收的 URL
SA_SERVER_URL = 'YOUR_SERVER_URL'
# 发送数据的超时时间,单位毫秒
SA_REQUEST_TIMEOUT = 100000
# 当缓存的数据量达到参数值时,批量发送数据
SA_BULK_SIZE = 100
# 初始化 Batch Consumer
consumer = sensorsanalytics.BatchConsumer(SA_SERVER_URL, SA_BULK_SIZE, SA_REQUEST_TIMEOUT)
# 使用 Consumer 来构造 SensorsAnalytics 对象
sa = sensorsanalytics.SensorsAnalytics(consumer)
# 程序结束前调用 close() ,通知 Consumer 发送所有缓存数据
sa.close()